시스템 아키텍처 설계 회고 및 고민
아키텍처 설계 회고
위 광고 트래킹을 처리할 수 있는 아키텍처를 고안하기 위해 다음과 같은 고민을 했다.
이와 같은 선택을 했던 과정에 대해 조금 정리해보며, 개인적으로 아쉬웠던 점이나 고민들을 작성해본다. 아키텍처 설계에도 정답이 없지만,, 뭐랄까 좋은 방향성도 있는 것 같고,, 각 상황별로 트레이드 오프는 혼자 고민한 내용이다.
스터디를 진행하며 아키텍처에 대해 받았던 피드백은 주로 기술 스택과 연관이 많았다. 실제 높은 성능을 요구하는 시스템은 내부적으로 어떤 구조로 설계되어 있는지에 대한 궁금증은 아직 남아 있는 것 같다.
광고 트래킹 시스템 아키텍처
대략적인 아키텍처 구성도이며 실제와 다르다
![]()
API에서 직접 RDB로 적재가 가능할까?
특정 TPS 미만에 좋은 성능의 database가 존재한다면 가능하다고 생각했다.
우리 시스템의 경우 초기 min-idle: 5, max:10 으로 설정되어 있었다. 모든 시스템이 동일한 설정으로 사용하고 있었다.
pod가 기본 5대였기 때문에 최소 25개의 connection pool이라면 보수적인 관점에서는 0.05ms * 500 TPS = 25,
평균적인 관점으로는 0.03ms * 500 TPS * 0.03 = 15개의 커넥션만 있으면 되기 때문에 최대 25 * 50 = 1250 tps까지 이론적으로 가능하다고 생각했다.
25~ 15 사이면 충분했고 pod 단위로보면 5개의 connection pool이라면 해당 tps를 처리할 수 있을 것이라고 판단했다.
그때 내가 고민하여 내렸던 결론은
- Aurora 적절히 튜닝시 이론상 500 TPS 이상 쓰기 가능
- Batch Insert 활용 가능: JDBC Batch로 10-100건 묶으면 성능 향상 (commit수 감소 = RTT 감소 pool 낭비 감소)
- Connection pool 최적화
(사용하던 aurora db spec 상 최대 1400개 이상의 connection pool을 유지할 수 있는 것을 확인하였고, vacuum은 infra 엔지니어가 고려해서 작업을 해두신 상황)
초기 db 직접 적재
약 500~600 TPS를 기준으로, 모바일 앱에서 광고 트래킹 API를 호출해 사용자 이벤트를 Aurora PostgreSQL에 직접 적재하는 구조로 시스템을 가져가려고 했다. 이 구조에서의 문제는 초당 약 500건의 commit이 DB로 유입되며, 트래픽이 목표 TPS를 초과할 경우 DB 부하 증가 및 장애로 이어질 가능성도 있다고 생각했다.
이에 따라 요청을 적절한 트랜잭션 단위로 묶어 commit 횟수를 줄이고, 이를 통해 DB 커넥션 사용량을 안정화 하기 위해 MyBatis 기반 batch insert 방식을 적용했다.
db batch insert 는 아래와 같은 방식으로 해결이 가능하며, 나의 경우 2번의 방식을 선택하였다. 그 이유는 foreach의 경우 단일 쿼리로 특정 row만 재처리하기에 어려움이 있으며, error handling을 처리하기 어렵다고 판단했다.
- foreach
- 이미 쿼리에 멀티 row insert 요청을 보내기 때문에 단일 쿼리로 특정 row만 재처리할 수 없다.
- ExecutorType.BATCH, SqlSessionFactory.openSession을 사용하여 직접 mapper.insert를 호출하고 sqlSession.flushStatements(), sqlSession.commit()
- 재처리나 error handling을 건별로 처리할 수 있어서 해당 방식을 선택
이때 고려해야 하는 것은 batch insert를 위한 내부 buffer 관리, linger, 그리고 실패건의 재처리 이다.
직접 적재의 문제점이 무엇이었을까?
결론적으로 TPS 요구사항이 바뀌었다. 더 높은 트래픽을 처리해야 했고 이를 해결하기 위해 고려해야 할 부분은 더 많아졌다.
광고의 비즈니스 관점에서 바라보았을 때 광고를 송출하는 db는 광고 센터에서 등록하고 수정하는 database와 동일한 것이다. 그리고 이 db는 트래킹을 처리하는 database와 동일하기 때문에 트래킹만 처리하기 위해 사용할 수 없다.
DB 직결구조의 문제점은 아래와 같다고 생각한다.
-
버스트 트래픽 처리 불가
- API 응답 시간 영향이 있다, 직접 적재시에 200-500ms의 DB 쓰기 대기가 발생 가능성
- Network issue -> timeout 발생
-
DB 장애/재시작 -> 요청 유실 (트래킹 서버 전체 중단)
- db connection pool 점유
- 데이터 유실에 대해 처리할 수 있는 방법이 없다. 즉 안정성이 떨어진다.
메시지 큐 사용
메시지 큐를 사용하여 아래와 같은 이점을 얻을 수 있다.
- 부하 분산
- 비동기 처리
- 재처리 로직
- 별도 consumer로 insert처리 자동 buffering 가능
AWS MSK와 SQS 비교
| 항목 | SQS | MSK |
|---|---|---|
| 메시지 보존 | 최대 14일, 소비 후 삭제 | 설정에 따라 무제한 (Tiered Storage) |
| 소비 | 모델경쟁 소비 (1개만 처리) | ConsumerGroup별 독립 소비 |
| 배치 | 최대 10건/호출 | 유연하게 조정 가능 |
| 스케일 | Serverless 자동 | 브로커/파티션 직접 관리 (Express는 자동) |
| 비용 | 기준요청 수 과금 | 인스턴스 시간 + 스토리지 |
| 운영 | Fully Managed | 부분 Managed (운영 개입 필요) |
운영 관점에서 msk에 대해 알기에는 시간이 조금 부족하다고 판단했고, 완전 관리형인 SQS를 선택하고 이후 더 높은 처리량이 요구되는 시점에 MSK를 사용하는 것이 적절하다고 생각했다. 현재 TPS 기준 SQS fifo queue로도 충분히 가능한 수준이다. 운영비용적인 측면에서도 sqs가 현저히 낮은 수준으로 message polling하는 요청 수별로 과금이 들어가는 것으로 알고 있고, 이후 유지보수 시에도 코드레벨 외에 aws에서 특별히 어려운 설정이나 관리가 필요한 부분이 없다. 반면 kafka의 경우에는 브로커, 파티션 등을 관리해야 한다.
뿐만 아니라, exactly once 중복 제거가 자동으로 가능하며, queue 속성 정보 자체가 쉽게 구성된 편이다.
Rabbit MQ
AWS SQS
(정리 예정)
데이터 유실관점
데이터 유실을 최대한 막기 위해 두 가지 레이어가 있었다.
1차: Producing 전 트래킹 이벤트 json 로깅 -> Fluent-bit → S3 → 파일 로그를 읽어 Batch를 통해 유실율 확인 유실이 있다면 원시 데이터 insert 2차: DLQ (알림 및 오류 적재)
1차 레이어의 경우 batch는 다른 개발자 분이 작업했다. Batch에서 저장된 원시 데이터와 file logging한 데이터를 20분 이전 파일 로그부터 확인하여 원본 테이블에 적재된 시간 기준으로 비교하여 집계를 통해 유실을 확인할 수 있도록 개발되어 있다.
재처리를 한다면 어디에 걸었어야했을까?
그럼 재처리를 어느 구간에 걸었어야 할까.. 우선 각각 행위 관점으로 살펴보면 책임은 아래와 같다.
[Producer 책임] API → SQS 발행 성공 보장 "데이터가 시스템에 진입했는가?"
[Consumer 책임] SQS → DB 적재 성공 보장 "진입한 데이터가 저장됐는가?"
Producer 구간 처리
결론 물론 아직까지 aws에서 장애가 났거나 오류가 발생하여 유실된 메시지는 없었다.
우선 메시지를 발행하는 시점에서 시나리오는 다음과 같다.
- SQS API throttling (application TPS 상한)
- Network timeout
- SQS 장애 (503)
client(광고가 송출되는 mobile app)는 우선 실패하더라도 항상 202 Accepted 응답 상태만 받도록 설계되어 있고 Queue에 메시지를 적재하지 못하는 상황은 주로 aws쪽의 일시적 오류나 장애 상황이라고 판단했다.
sdk 레벨에서의 재시도만 사용. 광고의 경우 유실을 절대 허용하지 않는 것이 아니다.
outbox 패턴을 붙이는 건 신뢰성은 보장될 수 있으나 복잡도만 추가하는 그리고 sqs는 api 서버에 burst를 흡수하도록 설계되었는데, rdb에 outbox를 끼워 넣으면 queue를 분리한 장점이 상쇄된다고 생각했다. produce 구간에 logging만 남기고 넘겼다. (파일로깅으로 처리 - 내가 개발하지 않았다)
Consumer 구간 처리
결론
메시지가 발행된 이후에 재처리를 해야하는 경우는 데이터 직렬화 문제이거나, 데이터 타입과 같은 삽입시 발생하는 문제로 database에 적재되지 못해서 발생하는 문제일 것이다. consumer의 경우 traffic burst에 직접적인 영향을 받지 않을 것으로 생각되어 기본값인 3회 재시도 최대 7초까지 수행하고 thread를 반환하고 dlq에 오류 데이터가 쌓일 것이다. dlq에 쌓인 데이터는 현재 로깅만 처리하고 별도 알림(cloud watch)을 붙이지는 않았다.
단기 장애라면 1~2, (1초 2초) 2초 이내에 다시 성공할 것이라고 생각한다. batch manager buffer에 넣고 리턴하기 때문에 재시도를 할때 이미 응답할 것이다.
가시성 타임아웃
Consumer 측 재처리를 알아보기 전에 Visibility Timeout 이 뭔지 살펴보는 게 좋을 것 같다. Consumer가 메시지를 receive하면 그 메시지는 visibility timeout 동안 다른 consumer에게 보이지 않는다. 이 시간 내에 메시지를 처리하고 delete하지 않으면, 메시지가 다시 큐에 visible 상태가 되어 재처리한다.
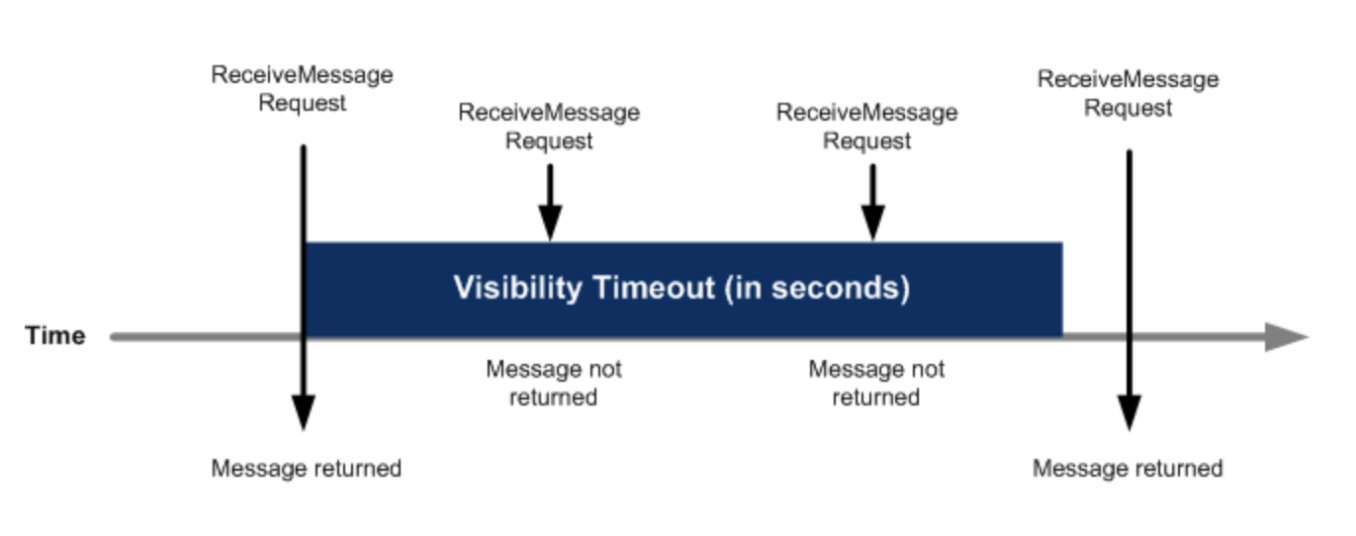
→ 이게 자동 retry의 핵심 메커니즘 이다.
Consumer 측에서 발생할 수 있는 오류 시나리오
- 네트워크 timeout
- DB 접근 불가
- 메시지 포맷 문제 (json 포맷, 테이블 문제)
실제로 3번 시나리오 외에는 발생한 문제는 없었다. staging 서버에서 잘못된 앱 배포로 인해 DLQ에 쌓이는 문제가 발생했다. (data 길이 초과, data type 문제)
우선 현재 구조에서 Consumer 측 재처리를 고려해야할 상황은 없다고 판단했다. 그 이유는 app의 header(user-agent, locale, ..) 의 데이터 외에는 전부 광고 송출시에 client에게 우리가 event type 별로 url을 queryString을 붙여서 내려주기 때문에 대부분의 데이터는 우리로부터 제공되었다.
이제 성능 최적화는 어떻게 해야할까?
내가 판단한 최적화 고려 순서
- 아키텍처/인프라 병목 해소
- replica 부족, vCPU throttle, network latency
- 애플리케이션 로직 최적화
- N+1 쿼리, 불필요한 객체 생성, blocking I/O
- 리소스 설정 조정
- Thread pool, Connection pool(해당되지 않음), Timeout(network) 값
- GC 튜닝 (최후의 수단)
- 위 3단계 이후에도 GC가 병목이면 그때 진행
- 최후의 수단으로 생각한 이유는 현재 스펙과 애플리케이션에 최적화 된 튜닝은 의미가 없다고 생각한다. 예를 들어 실제로 GC 튜닝으로 성능이 최적화가 되더라도 애플리케이션이 변한다면 이에 따라 GC 튜닝도 변경해야 한다고 생각한다.
- GC 튜닝은 warm-up을 제외하고 메모리 측면에서는 애플리케이션이 잘못 개발된 부분을 먼저 확인하는 게 맞다고 생각한다. 튜닝을 통해 메모리 누수를 막는 것은 결국 밑빠진 독에 물을 붓는 격이라고 생각한다. (객체를 할당하고 해제하지 못한 것이 문제이며 GC 튜닝 시에 실제 애플리케이션을 개선하지 않는 이상 신호를 억누르는 것일 뿐이라고 생각했다.)
실제 마주한 병목 구간은??
-
db 직접 적재 시, db라고 생각하였고, 그래서 connection pool을 기반으로 처리하려고 했음.
-
인프라 병목 - 성능 테스트 시에
- tcp connection timeout 오류 만남 tomcat thread pool size 확인 default 200, accept-count: 100 -> 충분하다고 생각..
- grafana의 pod cpu throttle 및 cpu usage 지표 확인 -> 거의 상한에 도달하여 안정화 되지 않음.
- k6 성능 테스트 결과 : p95와 p99간 이격이 컸다..http_req_duration, http_reqs
- (usage spike로 확인) -> vCpu, HPA 조정하여 connection timeout 오류를 해결
-
vCpu, HPA 조정 이후 여전히 heap 객체는 사용률이 100% 가까이 치고 올라가는 현상이 있었음.
- cpu usage는 어느정도 70% 미만으로 유지가 되었으나, heap만 높게
-
option tool 명령어에 heap의 min, max 사이즈가 256으로 잡혀있었음..
- 문의해보니 다른 시스템과 동일하게 초기에 설정해놓았을 뿐 계산을 통해 넣은 값이 아닌 것으로 확인하여 성능 테스트를 하며 최종적으로 2500 TPS를 발생 시켜도 heap의 메모리가 안정적으로 70% 미만으로 유지되는 값을 찾아 설정함 500 -> 700m
-
tracking을 처리하면서 애플리케이션에서 객체를 생성하는 로직이 크게 없었고, batch manager를 통해 적재하기만 했다. dto -> domain으로 변환하고 바로 batch manager buffer에 전송
내가 적용한 방법
- SQS 도입(DB 병목 구간 처리)
- 메시지 배치 전송(tracking-api - aws 구간)
- batch manager
- 네트워킹 구간(client - tracking-api 구간) pipe 확장 (pod vCpu, HPA)
- 추가로 ingest 구간에 서버 보호 (API Throttle)
- 애플리케이션 burst가 전부 tracking에만 자원을 할당하다가 리소스 이상의 요청시에는 서버 전체의 영향을 끼칠 수 있다고 생각되어 최대 목표 TPS 이상의 요청은 rate limiter를 통해 메시지를 유실하고 광고 송출부는 보호하는 것이 옳다고 판단했다.
- 추가로 ingest 구간에 서버 보호 (API Throttle)
성능테스트는 나중에 자세히 한번 작성해보려고 한다. 개인적으로 k6외에 고려했던 성능테스트 도구를 실제 코드와 함께 살펴보는 예제를 개발할 예정이다.
해당 플랫폼을 개발하며 개인적으로 많은 고민을 하여 개발했다고 생각하지만 지나고 나서 되돌아봤을 때 아쉬웠던 부분도 있다. JVM 메모리 사용량을 그라파나 대시보드에 직접 연동하지 못한 점, API Throttling을 tomcat Thread 기준(Bulkhead) 기준으로 작성하는 게 더 나은 판단이었는지 등,,
개인적으로 좋은 경험을 하며 단기적으로 많은 성장을 하며 좋은 경험을 했다고 생각한다.